

What is Kubernetes?
Kubernetes tends to be a portative, expandable open-source custom software container that allows automating the deployment, scaling, and management of computer applications. It has a large ecosystem that is rising rapidly. Cubans are readily available in terms of services, assistance, and money.
In today’s fast-paced digital world, understanding tools that streamline application deployment and management is crucial. This brings us to a key question many developers and IT professionals ask: what is Kubernetes? Essentially, Kubernetes, often abbreviated as K8s, is a powerful open-source system for automating the deployment, scaling, and management of containerized applications. It directly answers the critical need of what is Kubernetes used for by providing a robust framework to reliably run complex distributed systems and microservices. For those looking to master both containerization and orchestration, and gain practical, in-depth knowledge, our Docker Kubernetes Training offers a comprehensive learning pathway. Understanding what are Kubernetes’ core principles and architecture is the foundational step towards leveraging its immense capabilities for efficient, resilient, and scalable application delivery.
The name Kubernetes is Greek, which means steward or pilot. The Kubernetes project, i.e., Google’s Cloud Native Computing Base concept, was launched in 2014 by Google. Over 15 years of experience in creating workloads on a scale, Kubernetes incorporates the best race ideas and practices through Google. It aims to provide a ‘framework that will simplify the deployment, scaling, and operation of application containers across host clusters.’ It works with a variety of container tools, including Docker.
Many cloud providers provide a framework or infrastructure based on Kubernetes as providers (PaaS or IaaS) to incorporate Kubernetes as a platform application. Many of the suppliers still supply the products.
Understanding the Building Blocks: What are Kubernetes Components?
Containers are an excellent way to integrate and execute the program. The systems that run the applications must be addressed, and there must be no downtime in the development environment. For example, if the container is down, a new container must start. If a computer regulates this operation, wouldn’t it be easier?
This is how the Kubernetes rescue is carried! Kubernetes provides a forum for the resilient control of distributed systems. It ensures scaling, and failure of the program includes user patterns and more. Kubernetes, for example, can easily manage the deployment of a canary framework.

Uses of Kubernetes:
Kubernetes is a popular container management framework that automates the deployment and management of containers. The next big wave of cloud computing is Kubernetes (k8), and it’s easy to see why businesses are switching their technology and architecture to a cloud-based data-driven environment.
● Orchestra of containers
Containers are wonderful. It gives you a convenient way to package and execute services, provides process isolation, immutability, efficient use of resources, and creates lightweight.
However, you will ultimately end up with hundreds, including thousands of containers when it comes to producing containers. The containers must be deployed, handled, linked, and actualized; you would need a whole team dedicated to this if you want to do this manually.
Containers are not sufficient to run; you must be able to:
➔ Integrate the modular modules and arrange them
➔ Scale-up and down according to demand
➔ Make it tolerant of fault.
➔ Provides cluster coordination
You may ask: shouldn’t it all be containers? The answer is, boxes are just a small part of the puzzle. With tools on top of containers like Kubernetes, the real advantages are extracted. Now, these tools are called container schedulers.
● Ideal for use in multi-cloud
With many businesses today focusing on architectural microservices, it is not surprising that containers and tools are so famous for managing them. The Microservice architecture makes dividing your application into smaller container components that can then be run in various cloud environments, allowing you to select the best host for your requirements. Kubernetes is useful because it is designed to be used anywhere so you can deploy to private, public, or hybrid clouds to access users with improved availability and protection. Their versatility is significant. You can see how Kubernetes can help you escape possible risks by locking the supplier.
Sign Up For Kubernetes and Docker Certification Training
● Update and deploy applications on a quicker time to market
Kubernetes helps teams to keep up with new software development standards. Without Kubernetes, large groups will have to write their workflows manually. Containers, paired with an orchestration tool, can handle your devices and services to increase the application stability while reducing the time and money spent on DevOps.
● Better application management
Containers permit smaller pieces of the application to be broken down and managed by an orchestration tool such as Kubernetes. This facilitates the coding and testing of particular inputs and outputs.
As previously mentioned, Kubernetes has integrated functions such as automatic healing and rolling/rolling back and manages containers for you effectively.
To make even more development, in comparison to a deployment script, Kubernetes enables declarative state expressions of the desired status, meaning that a planner can follow the cluster and execute behavior if the current state does not fit the desired condition. Schedulers can be interpreted as operators who continuously track the system and address variations between the expected and actual forms.
You will use it to deploy, integrate, and scale (or scale) these services without downtime. This is mobile. It could run on a private or public cloud. It could be run in a hybrid environment or on the spot. Without changing (mostly) any step of deployment/management, you can move the Kubernetes cluster from one hosting provider to another. Cubers can easily be extended to fulfill almost any requirement. The modules to be used can be selected, and additional features can be designed and plugged in. Kubernetes can determine where to run and how to manage the state you specify. Kubernetes can position service replicas on the most suitable server, restart and scale them as needed. Self-healing is part of its design from the beginning.
On the other hand, there will soon be self-adaptation. The addition of substantial added value in Cubanets is zero downtime, fault tolerance, high availability, scaling, scheduling, or self-healing. For stationary applications, you can use this to mount volumes. It helps you to store sensitive information as secrets. You can use it to check your services’ fitness. It can load and track balance requests. It allows you to locate resources and access logs quickly.

Features of Kubernetes
● Automates numerous manual processes: Kubernetes will monitor which server will host the container, how it will be deployed, etc.
● Contacts many container groups: Kubernetes can handle more clusters simultaneously.
● Additional services provision: Kubernetes provides security, networking, and storage services as well as container management.
● Self-surveillance: Kubernetes continuously tests the health of nodes and containers
● The horizontal scaling: Kubernetes makes it easy and quick to scale resources vertically and horizontally.
● Storage: Kubernetes mounts and adds your chosen storage device to run apps
● Automated rollouts and reversals: Kubernetes will roll back for you if something goes wrong after adjusting your submission.
● Balancing containers: Cubans often know where containers can be positioned by measuring the “right location” for containers.
● Run all over: Kubernetes is a tool open source that allows you to use on-site, hybrid, or public cloud resources to move workloads wherever you like. Run all over.

What is a Kubernetes cluster?
The key piece can be understood: A cluster is a group or many nodes running your containerized applications. You are running the cluster, and all that it entails – that is, you are managing Kubernetes applications.
Key differences between Kubernetes and Ansible
Ansible is a software automation tool that deploys applications and organizes complex IT activities, such as rolling updates or ongoing deployments. Kubernetes, on the other hand, is a method for the orchestration of Docker containers. It handles working loads and uses preparation nodes to ensure its condition meets the needs of the users.
In other words, Ansible deploys host changes while Kubernetes handles and maintains containers running correctly.
Ansible is an excellent tool for front-end developers, particularly where some programming is needed. Kubernetes is the most suitable application for broad applications.
It is like comparing apples to oranges, based on the features of both instruments. Admittedly, the two DevOps tools handle configuration management, but they have limited overlap for their use.
Want to Upskill to get ahead in your career? Check out the DevOps Online Training
What is a Kubernetes service?
A Kubernetes service is, as the Kubernetes documentation states, “an abstract way of exposing an application running as a network service on several pods.” “Kubernetes gives a group of puppets their IP addresses and a single DNS name and can balance the load over them.”
But pods have a short lifetime sometimes. With the pods coming and going, services help other pods “find out which IP address they are connected to and monitor.”
Case-Study: Kubernetes powering Pokemon Go
Horizontal scaling is the real challenge for almost all large applications. However, in the case of Pokémon Go, vertical scaling is the main problem because of a shift in the real-time environment of the player, which all other users must represent. The main challenge for Kubernetes is to scope each user’s performance and needs at the same time. Not only did it contribute to the vertical and horizontal scaling of containers, but it also met expectations. The servers had a basic expectation of up to 5x, but with the aid of Kubernetes, it increased by 50x.
With the support of the Kubernetes, Pokemon Go was powered. It’s a very famous 2017 game, and the Kubernetes have been the reason for that. Niantic is designed for Android and IOS devices. Every day there were 50 million updates and more than 20 million active users. It’s been launched in North America, Australia, and New Zealand. It has encouraged users to fly nearly 5.4 million miles a year. The past of this app is in Java and libGDX and has been hosted in the Bigable NoSQL database in the Java Cloud and Google Cloud.
Kubernetes architecture
Basics of Kubernetes Architecture
- Master manages the clusters and the nodes within the cluster.
- Nodes are hosting containers within them that live in different PODS.
- PODS is a logical set of containers that communicate with each other for an application.
- Replication Controller is a Master resource, and it ensures that every requested POD is running at all times.
- A service is a master object that provides load balancing across the replicated PODS community.
Below is the architecture diagram for Kubernetes
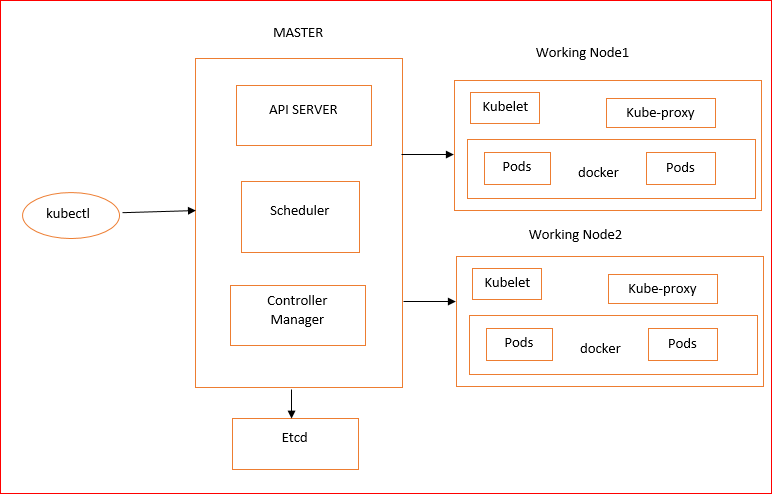
Kubernetes Architecture
The main components of Kubernetes Architecture :
● Master nodes
● Worker/Slave nodes
● Distributed key-value store
kubectl
The last thing – a tool for interacting with the API service and sending commands to the master node
Docker
Each worker node will be run by Docker, running the configured caps. The photos are downloaded, and containers are started.
kubelet
The kubelet takes the apiserver pod configuration to ensure that the containers listed are up and running. This is the worker service that communicates with the master node.
It also interacts with etc. to collect information on newly developed services and to write the data.
Kube-proxy
The Kube-proxy serves as a load balancer and a network proxy for a single working node operation. It provides TCP and UDP packets with network routing.
Node:
A node is a machine, whether physical or virtual. Kubernetes is not created. You can build or manually install cloud-based systems such as OpenStack or Amazon EC2. So before you use Kubernetes to deploy your applications, you need to develop your necessary infrastructure. From that point on, however, it can define virtual networks, Storage, etc. For example, to define networks, you might use OpenStack Neutron or Romana to force them out of Kubernetes.
Pods
A pod is one or more of the containers that logically go together. Pods are running on nodes. Pods are running together as a logical unit. So they share the same content. They all share the shared IP address, but they can access other addresses through the localhost. And they could share the Storage. But they don’t all need to run on the same machine as containers can run on more than one device. One node is capable of running several pods.
The pods are cloud-conscious. E.g., you might spin two Nginx instances and allocate them to a public IP address to the Google Compute Engine (GCE). To do this, you would start the Kubernetes cluster, configure a GCE link, and then type something like:
Kubectl expose my-nginx deployment – port=80 – type = LoadBalancer

Master
It is the starting point for the management of the Kubernetes cluster in all administrative tasks. There might be more than one master node in the cluster to search for error tolerance. More than one master node places the device in a High Availability mode, one of which is the main node in which all the tasks are performed.
To control the cluster state, in which all master nodes bind to it.
API Server
The API server is the input point for all REST control commands used for cluster control. It processes, validates, and performs the related business logic for REST applications. Somewhere the resulting state has to remain, and this leads us to the next master node part.
etcd Storage
etcd is a simple, distributed, consistent store of key value. It is used mostly for shared settings and service discovery.
The CRUD API provides a REST API and GUI for registering watchers on individual nodes, allowing the rest of the cluster to report changes to their configuration reliably.
An example of Kubernetes data stored in etcd is planning, creating, and deploying jobs, pod/service details and state, namespaces, replication information, and more.
Scheduler
Usage of the scheduler component to deploy optimized pods and services to the nodes.
The scheduler has knowledge about available resources for cluster members and those appropriate to operate the configured service and can determine where a special service is to be deployed.
Controller-manager
In the master node, you can optionally run various kinds of controllers. The manager of controls is an embedding daemon of such.
A controller uses an apiserver to track the cluster’s shared status to correct the current state to transform this into the desired state.
The replication controller, which controls the number of pods in the system, is an example of that controller. The user configures the replication factor, and the controller is responsible for recreating or removing an additional timed pot.
Other examples include the controls of endpoints, namespace controllers, and the controller of service accounts, but we will not go into depth here.
Kubernetes Vs. Docker
The key differences between Kubernetes and Docker are as follows:
● The creation of Kubernetes is by Google and the output of Docker Swarm by Docker Inc.
● Kubernetes autoscaling is provided, while Docker Swarm is not autoscaling supportive.
● Up to 5000 nodes are supported by Kubernetes, while Docker Swarm keeps over 2000.
● Kubernetes is less detailed and more personalizable, whereas Docker Swarm is more complete and personalizable.
● The tolerance for Kubernetes is low, while the Docker tolerance is high.
Interested to begin a career in DevOps? Enroll now for Devops Foundation Certification
Why is Kubernetes so popular?
Kubernetes is gaining popularity because of the advantages such as:
● We are creating and deploying agile applications.
● Ongoing development, integration, and implementation.
● Separation of issues between Dev and Ops.
● Surfaces for observability use health and other indications and details and indicators for the operating system.
● Test, growth, and output environmental consistency: runs on the same cloud as on your desktop.
● Portability for cloud and OS deployment – Runs on RHEL, Ubuntu, CoreOS, big public clouds, online and elsewhere.
● Management is application-focused.
● Microservices are loosely connected, scattered, elastic, free.
● Isolation of resources: predictable application efficiency.
● Usage of resources: high productivity and density.
Career in Kubernetes
Automation solves several problems, but there is someone else – probably more creative – who has to do it. This is one reason why recruiting from Kubernetes continues to increase this year. The interconnection between hybrid and multi-cloud environments, cloud-oriented creation, and containers increases the need for IT professionals who can spin these plates then Kubernetes is a chance to swing off a stale job or retrace your career. The container orchestration technology seems to be a safe bet for sustainable growth in the “Trends always be learning” culture of IT – and the popular advice in IT professions.
The slogan of Kubernetes has been the best orchestration method in today’s market. It attracts multiple experienced professional people who want to improve in their careers.
The fast-growing technology in 2020 is Kubernetes. You should be aware of the fundamental and advanced subjects of Kubernetes in your resume, whether you are a developer, cloud architect, software engineer, IT engineer, programmer, or even system administrator. Also, Kubernetes is sponsored by major companies such as Microsoft, RedHat, and IBM, which have made it the best tool for container management in recent years. The New York Times, Open AI, and Sound Cloud use Kubernetes, as do multinationals such as HUAWEI, Pokemon, Box, eBay, Ing, Yahoo Japan, SAP. However, the industry lacks trained Kubernetes practitioners.
Update your skills with DevOps AWS Training
What are the Kubernetes benefits for companies?
● Controlling and automating installations and updates
● Save money by the more effective use of hardware through leveraging infrastructure services.
● Orchestrate several hosts of containers
● Solve several common problems by grouping containers into “pods” (see the last post!). The proliferation of containers
● In real-time, scale resources and applications.
● Application verification and autocorrection

Why become a certified Kubernetes(K8’s) professional?
Certified Kubernetes professional has many advantages:
● Stand out of the crowd. Stand out. Your currency looks nice and stands out from the competition with a certification from Kubernetes. With businesses increasingly depending on k8s, your experience will be a direct advantage.
● Get a salary hike. Get a pay bump. You have a tremendous chance for improved salaries with a top qualification such as the CKA or CKAD. Such tests are not a simple job. Hence companies that pursue k8s engineers are prepared to pay more because certificates prove that not only do you have the expertise but that you really can grasp the platform.
● Attain personal growth. The passing of these exams is a personal reward: leisure time and fun are sacrificed to study and practice, so it is rewarding to pass the exam itself. You can then even move to another ability to concentrate.
● They become experts in Kubernetes. The definitions of Kubernetes are more straightforward and nearly secondary after the analysis. Following the annoyance as a beginner to the k8, the joy in learning is worthwhile and unprecious.
● Diversify your knowledge and understanding and extend it. The K8s architecture is focused on 12 applications based on 12-factor principles, so you have a strong basis in 12 application principles by being certified as K8s, which support several SaaS applications. Speak of your skills development.
But to become a certified Kubernetes professional, you need to join offline/online courses from reputed institutes like 3RI Technologies. They guide and coach you, and getting certification becomes easier.
3RI Technologies provides Online DevOps Training as well as DevOps Training in Pune where you can enhance your knowledge about DevOps tools.
FAQ:
Where can I run Kubernetes?
Kubernetes is flexible and can work on various computers. You can use it on your personal computer to learn and practice. For larger-scale use, companies often run Kubernetes on powerful servers provided by cloud services like Amazon Web Services (AWS) or Google Cloud Platform (GCP). It can also be set up on servers in your company’s own data center if they have one.
What is “enterprise Kubernetes?”
Enterprise Kubernetes is comparable to creating an advanced workspace tailored for applications within large companies. In this context, the focus is on configuring Kubernetes, a robust container orchestration platform, to efficiently manage a diverse array of applications and services. The emphasis is on establishing a meticulously organized environment where applications can thrive seamlessly and securely. This entails addressing the intricate requirements of a complex business landscape, ensuring that the deployment, scaling, and management of applications align with the specific needs and standards of a sizable enterprise. Enterprise Kubernetes provides a structured and efficient framework for orchestrating the diverse elements of an organization’s software ecosystem, promoting scalability, security, and streamlined operations.
How do I start using Kubernetes?
To start with Kubernetes, first, familiarize yourself with containers – these are like individual components of your applications. Kubernetes serves as the tool to organize and manage these components. Set up Kubernetes on your computer using tools like Minikube to create a small environment for practice. Learn about Kubernetes concepts like Pods and Deployments to help you design and manage applications. As you gain confidence, explore more advanced features, and for production environments, consider leveraging managed Kubernetes services offered by cloud providers. This hands-on approach will help you grasp the essentials of Kubernetes and its powerful capabilities in orchestrating containerized applications.
What is Kubernetes monitoring?
Monitoring in Kubernetes is like having a vigilant assistant who constantly checks the pulse of your applications. It involves keeping an eye on things like how much memory your apps are using, whether they are responding quickly, and if they are working well together. Monitoring tools like Prometheus and Grafana act as this assistant, providing insights into your applications’ health.
Why is Kubernetes monitoring important?
Monitoring is crucial because it is like having early-warning sensors. Just like a car dashboard shows if your car is running smoothly, Kubernetes monitoring ensures your applications are healthy. It enables quick identification and resolution of issues, assuring application stability. It helps catch issues before they become big problems, ensuring your apps are always in good shape. It helps you understand how your apps and the tech supporting them are performing. It supports compliance with service-level agreements (SLAs) by ensuring optimal performance.
How to do Kubernetes monitoring?
Monitoring with Kubernetes is analogous to having a collection of smart tools. Prometheus serves like a detective, gathering information about your apps. Grafana is a tool that turns data into easy-to-understand visuals, making it look good and helping you understand it better. This tool gathers metrics from various Kubernetes components and display graphs and alarms. Furthermore, cloud providers frequently include monitoring tools with their managed Kubernetes services. They give a clear picture of how your applications function when used together.
What is Kubernetes Support?
Kubernetes support is like having expert help for businesses using Kubernetes. Whether it is from specific companies or the broader tech community, this support assists in setting up, managing, and fixing issues with Kubernetes clusters. It is akin to having a reliable friend who not only gives advice but also provides training to understand Kubernetes better. When things go wrong, these experts step in to quickly solve problems. Importantly, this support doesn’t just end there – it is ongoing, making sure that using Kubernetes stays smooth and successful. It is like having a knowledgeable friend who supports you in the world of Kubernetes.
What is Kubernetes Orchestration?
Kubernetes orchestration is the automated coordination and control of containerized applications within a Kubernetes cluster. Imagine it as the traffic controller, ensuring that every containerized application work seamlessly and avoid collisions. This process involves the routine tasks of deploying applications, adjusting their scale to meet demand, upgrading them when necessary, and maintaining their overall health. In practical terms, it is like having a maestro who manages the entire performance seamlessly – starting new applications, adjusting the number of instances to handle varying workloads, updating applications to the latest versions, and making sure everything operates smoothly. Kubernetes orchestration is the behind-the-scenes coordination that keeps containerized applications in sync and running efficiently within the dynamic environment of a Kubernetes cluster.
What is Kubernetes multi-cluster?
Kubernetes multi-cluster is like having many computer neighbourhoods, where each neighbourhood, or Kubernetes cluster, independently manages and hosts applications. In this setup, these clusters can operate on their own terms or collaborate as part of a larger system, offering flexibility in management. The approach is often used to distribute workloads efficiently, allowing each cluster to focus on specific tasks. Furthermore, multi-cluster setups enhance fault tolerance; if one cluster faces issues, others continue working independently. This decentralized model enables customization, catering to the diverse needs of organizations, making it akin to managing a network of self-sufficient computer neighbourhoods.